As I explore Data Factory, I’ve started to compile a list of lessons learned. Some things that may trip up a new user of the platform (and have certainly tripped me up as I’ve learned about it).
The first of these relates to computed columns in SQL Server. According to Microsoft, “a computed column is a virtual column that isn’t physically stored in the table, unless the column is marked PERSISTED” and as you’d expect, it “can’t be the target of an INSERT or UPDATE statement”. However, Data Factory doesn’t recognise computed columns in SQL Server and will still try to insert data when a pipeline is run, only for it to fail.
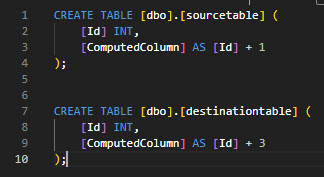
In order to prove this, I create two tables in my SQL Server database, both of which contain a computed column of the same name.
CREATE TABLE [dbo].[sourcetable] (
[Id] INT,
[ComputedColumn] AS [Id] + 1
);
CREATE TABLE [dbo].[destinationtable] (
[Id] INT,
[ComputedColumn] AS [Id] + 3
);
I populate the source table with some data (it doesn’t really matter what data, so long as we have some values in the computed column).
Jumping over to Data Factory Studio, I create the linked service for my database, the datasets for the source and destination tables, and a simple pipeline.
Then I add a Copy Data activity to the pipeline that will copy data from [dbo].[sourcetable] to [dbo].[destinationtable]. Importing the schemas in the Mapping pane for the Copy Data activity will result in the two computed columns being automatically mapped to each other because they have the same name.
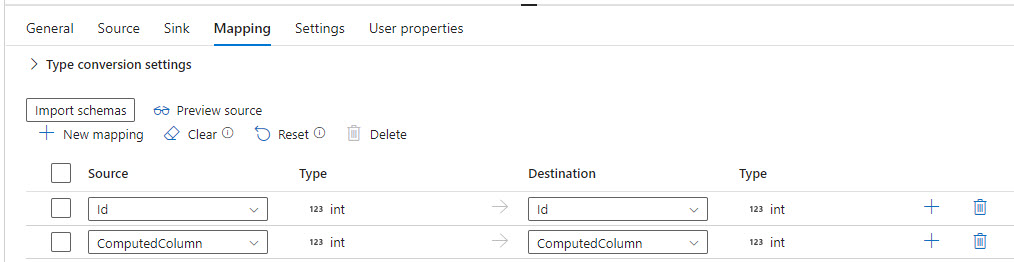
This mapping passes validation but as soon as you debug the pipeline, it will fail because you can’t insert data into a computed column.

Removing the computed column from the Copy Data activity’s mapping will fix the problem, and having done that, my next attempt to debug the pipeline will succeed.

I can confirm this by querying the tables via Azure Data Studio, and I see that the data has been copied from source to destination for the non-computed Id column and the computed column in the destination table calculates the values as expected.
SELECT * FROM [dbo].[sourcetable];
SELECT * FROM [dbo].[destinationtable];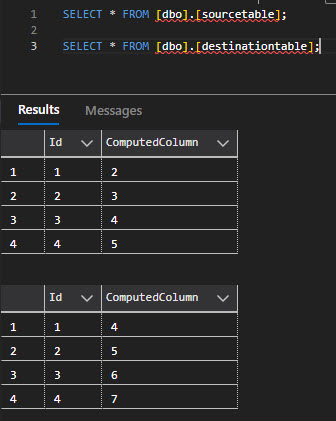
However, when using the Data Factory Studio, computed columns must be manually removed from each Copy Data activity that is impacted by them. Data Factory can’t identify computed columns as part of the schema import and it doesn’t advise you which destination columns are computed when you review the mappings. So if you have a lot of tables with computed columns in the destination, that manual work can really build up!
Be First to Comment