Aim: To utilise Azure Data Factory’s “Auto create table” feature to temporarily store data as part of an ETL pipeline.
There are some situations where you will want to use Azure Data Factory to copy data to a sink table that doesn’t exist independent of the ETL pipeline. In these cases, the table will need to be temporarily created, e.g. to store data until it is transformed and loaded to the final sink table.
While the Copy Data activity has an “Auto create table” option for Azure SQL and SQL Server, I’ve struggled to find much in the way of official documentation on how to get this working cleanly.
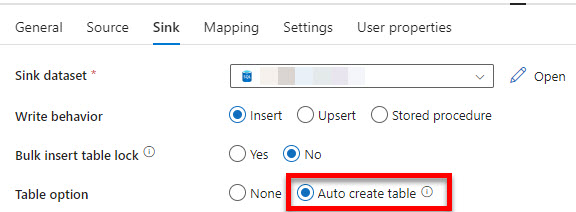
After some trial and error, the following is the process that works for me.
In this scenario, I am copying User Name data from a source to an auto created table, named [tempUserName], in the destination database. The User Name data is then joined to User Email data in the destination database and inserted into the final [UserDetail] table.
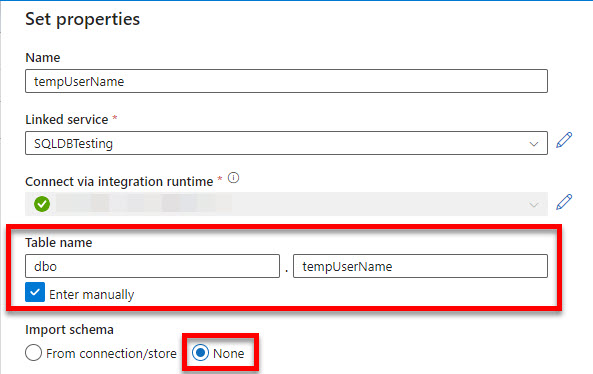
The first step is to create the Linked Services for the source and sink databases as usual. I also create the Dataset for the source [UserName] table, importing its schema from the connection. Then, when creating the Dataset for [tempUserName], I manually enter the table name rather than picking one from the list. Remember, at this point, the [tempUserName] does not yet exist. As a result, there is no schema to import.
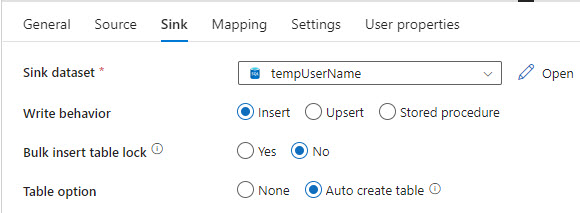
Next, I create the Pipeline with a Copy Data activity to copy the data from the source [UserName] table to [tempUserName]. On the Sink tab, I choose the “Auto create table” option.
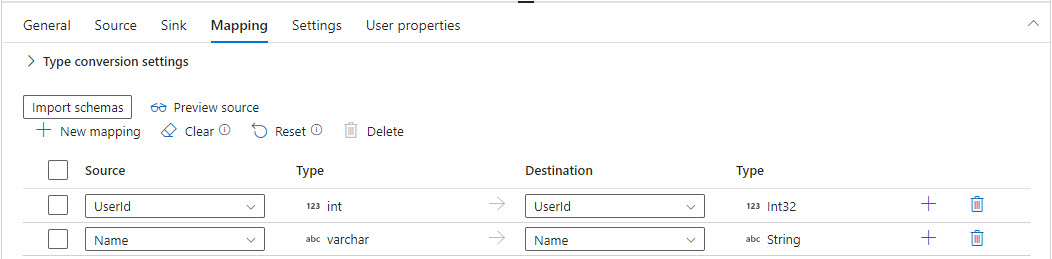
On the Mapping tab, I have the option to either use the “Import schemas” feature or to create the mapping manually. Regardless of which I choose, the column names and datatypes are restricted by the source table’s columns.
Once the Copy Data activity has copied the User Name data to [tempUserName], I use a Script activity to join the User Email data to it and insert the results to the [UserDetail] table. Once that’s done, the script will drop the [tempUserName] table as it’s no longer needed. Note that because the script inserts data and drops a table without returning a resultset to ADF, I have chosen the NonQuery option.
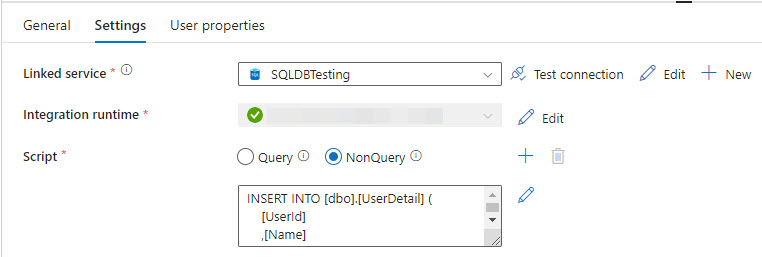
INSERT INTO [dbo].[UserDetail] (
[UserId]
,[Name]
,[Email]
)
SELECT t.[UserId]
,t.[Name]
,e.[Email]
FROM [dbo].[tempUserName] t
INNER JOIN [dbo].[UserEmail] e ON t.[UserId] = e.[UserId];
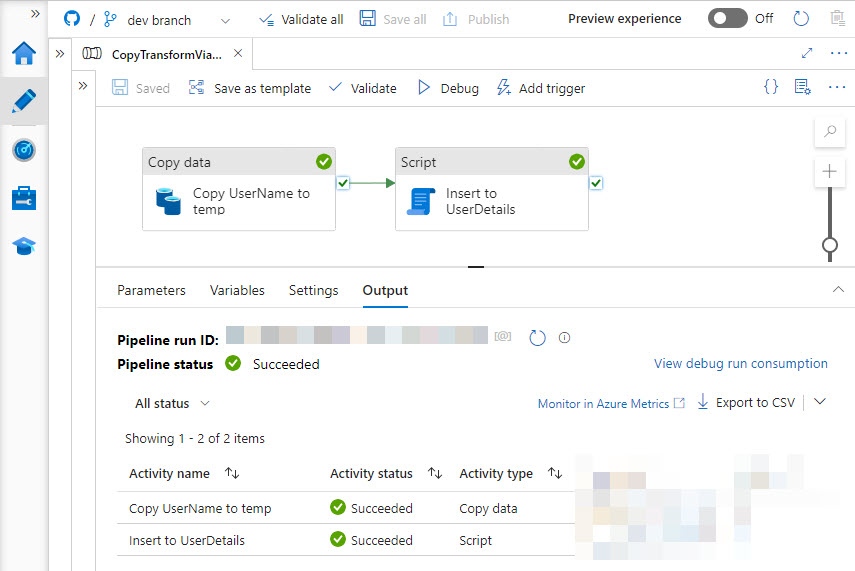
DROP TABLE IF EXISTS [dbo].[tempUserName];When I debug the Pipeline, it all works smoothly.
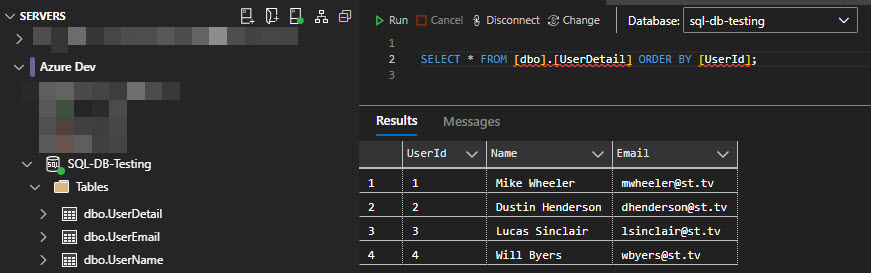
And when I check my destination database, I can see that the User Name and Email data now resides in the [UserDetail] table and that the [tempUserName] table does not appear in the table list as it was deleted by the script.
Note:
- If a table with the same name and schema as the auto created table exists in the destination database, the Pipeline will succeed as it will use this table. It effectively takes a “create table if not exists” approach. This will also result in any existing data in the table being incorporated into the ETL – which may not be the desired outcome!
- If a table with the same name but different schema exists in the destination database, the Pipeline will fail as its schema will not match ADF’s expectation based on the schema of the source table.
Be First to Comment